推荐:使用NSDT场景编辑器助你快速搭建可编辑的3D应用场景
移动设备上的智能助手具有非常先进的基于语言的交互,用于执行简单的日常任务,例如设置计时器或打开手电筒。尽管取得了进展,但这些助手在支持移动用户界面 (UI) 中的对话交互方面仍然面临限制,其中执行了许多用户任务。例如,他们无法回答用户关于屏幕上显示的特定信息的问题。代理需要对图形用户界面(GUI)来实现此类功能。
先前的研究已经调查了几个重要的技术构建块,以实现与移动UI的对话交互,包括汇总移动屏幕以便用户快速了解其用途,将语言指令映射到 UI 操作和图形用户界面建模以便它们更适合基于语言的交互。但是,其中每个都仅解决会话交互的有限方面,并且在策划大规模数据集和训练专用模型方面需要大量工作。此外,移动 UI 上可能发生广泛的对话交互。因此,必须开发一种轻量级和可推广的方法来实现对话交互。
在“使用大型语言模型启用与移动 UI 的对话交互”,在CHI 2023,我们研究了利用大型语言模型(LLM)实现与移动UI的各种基于语言的交互的可行性。最近预先训练的LLM,例如手掌,在收到一些目标任务示例提示时,已经表现出适应各种下游语言任务的能力。我们提出了一套提示技术,使交互设计师和开发人员能够快速原型化和测试与用户的新颖语言交互,从而在投资专用数据集和模型之前节省时间和资源。由于LLM仅将文本令牌作为输入,因此我们提供了一种新颖的算法来生成移动UI的文本表示。我们的结果表明,这种方法在每个任务中仅使用两个数据示例即可实现竞争性能。更广泛地说,我们展示了LLM从根本上改变对话交互设计未来工作流程的潜力。
 |
| 动画显示了我们使用LLM实现与移动UI的各种对话交互的工作。 |
LLM通过提示支持上下文中的少数镜头学习 - 而不是为每个新任务微调或重新训练模型,人们可以使用目标任务中的一些输入和输出数据示例提示LLM。对于许多自然语言处理任务,例如问答或翻译,少镜头提示具有竞争力基准方法训练特定于每个任务的模型。但是,语言模型只能接受文本输入,而移动 UI 是多模式的,在其中包含文本、图像和结构信息视图层次结构数据(即包含 UI 元素详细属性的结构数据)和屏幕截图。此外,将移动屏幕的视图层次结构数据直接输入LLM是不可行的,因为它包含过多的信息,例如每个UI元素的详细属性,这可能会超过LLM的输入长度限制。
为了应对这些挑战,我们开发了一套技术来提示使用移动UI的LLM。我们贡献了一种算法,该算法使用深度优先搜索遍历以将 Android UI 的视图层次结构转换为 HTML 语法。我们还利用思维链提示,这涉及生成中间结果并将它们链接在一起以达到最终输出,以引出LLM的推理能力。
 |
| 动画显示使用移动 UI 进行少量镜头提示 LLM 的过程。 |
我们的提示设计从解释提示目的的序言开始。序言后面是多个示例,包括输入、思维链(如果适用)和每个任务的输出。每个示例的输入都是 HTML 语法中的移动屏幕。在输入之后,可以提供思维链以从LLM中引出逻辑推理。此步骤未显示在上面的动画中,因为它是可选的。任务输出是目标任务的预期结果,例如,屏幕摘要或用户问题的答案。提示中包含多个示例可以实现少数镜头提示。在预测过程中,我们向模型提供提示,并在末尾附加一个新的输入屏幕。
实验我们对四个关键的建模任务进行了全面的实验:(1)屏幕问题生成,(2)屏幕摘要,(3)屏幕问答,以及(4)将指令映射到UI操作。实验结果表明,我们的方法在每个任务中仅使用两个数据示例即可实现竞争性能。
 |
给定移动 UI 屏幕,屏幕问题生成的目标是合成与需要用户输入的 UI 元素相关的连贯、语法正确的自然语言问题。
我们发现LLM可以利用UI上下文来生成相关信息的问题。LLM在问题质量方面明显优于启发式方法(基于模板的生成)。
 |
| LLM 生成的屏幕问题示例。LLM 可以利用屏幕上下文生成与移动 UI 上每个输入字段相关的语法正确的问题,而模板方法则不足。 |
我们还揭示了LLM将相关输入字段组合成一个问题以进行有效沟通的能力。例如,询问最低和最高价格的过滤器合并为一个问题:“价格范围是多少?
 |
| 我们观察到LLM可以利用其先验知识组合多个相关的输入字段来提出一个问题。 |
在评估中,我们征求了人类对问题的语法是否正确(语法)以及与生成它们的输入字段相关(相关性)的评分。除了人工标记的语言质量外,我们还自动检查了LLM如何覆盖需要生成问题的所有元素(覆盖范围F1).我们发现LLM生成的问题具有近乎完美的语法(4.98 / 5),并且与屏幕上显示的输入字段高度相关(92.8%)。此外,LLM在全面覆盖输入领域方面表现良好(95.8%)。
| 模板 | 2发法学硕士 | |||||||
| 语法 | 3.6(满分 5 分) | 4.98(满分 5 分) | ||||||
| 关联 | 84.1% | 92.8% | ||||||
| 覆盖率 F1 | 100% | 95.8% |
屏幕摘要是自动生成描述性语言概述,涵盖移动屏幕的基本功能。该任务可帮助用户快速了解移动 UI 的用途,这在 UI 不可视访问时特别有用。
我们的结果表明,LLM可以有效地总结移动UI的基本功能。它们可以生成比屏幕2个单词我们之前使用特定于 UI 的文本引入的基准测试模型,如下面的彩色文本和框中突出显示的那样。
 |
| 由 2 发 LLM 生成的示例摘要。我们发现LLM能够使用屏幕上的特定文本来撰写更准确的摘要。 |
有趣的是,我们观察到LLM在创建摘要时利用他们的先验知识来推断UI中未显示的信息。在下面的示例中,LLM 推断地铁站属于伦敦地铁系统,而输入 UI 不包含此信息。
 |
| LLM利用其先验知识来帮助总结屏幕。 |
人工评估将LLM摘要评为比基准更准确,但他们在以下指标上的得分较低BLEU.感知质量与指标分数之间的不匹配产生共鸣近期工作显示LLM可以写出更好的摘要,尽管自动指标没有反映它。
| 左:自动指标的屏幕摘要效果。右:由人工评估人员投票的屏幕摘要准确性。 |
给定移动 UI 和一个询问有关 UI 信息的开放式问题,模型应提供正确答案。我们专注于事实问题,这些问题需要根据屏幕上显示的信息进行回答。
 |
| 屏幕质量检查实验的结果示例。LLM明显优于现成的QA基线模型。 |
我们使用四个指标报告性能:完全匹配(与基本事实相同的预测答案)、包含 GT(答案完全包含基本事实)、GT 子字符串(答案是基本事实的子字符串)和微型F1评分基于整个数据集中预测答案和基本事实之间的共享单词。
我们的结果表明,LLM可以正确回答与UI相关的问题,例如“标题是什么?LLM的表现明显优于基线QA模型 DistillBERT,达到 66.7% 的完全正确率。值得注意的是,0-shot LLM的精确匹配得分为30.7%,表明该模型的内在问答能力。
| 模型 | 完全匹配 | 含有 GT | GT的子字符串 | 微型F1 | ||||||||||
| 0发法学硕士 | 30.7% | 6.5% | 5.6% | 31.2% | ||||||||||
| 1发法学硕士 | 65.8% | 10.0% | 7.8% | 62.9% | ||||||||||
| 2发法学硕士 | 66.7% | 12.6% | 5.2% | 64.8% | ||||||||||
| 蒸馏伯特 | 36.0% | 8.5% | 9.9% | 37.2% |
给定移动 UI 屏幕和自然语言指令来控制 UI,模型需要预测对象的 ID 以执行指示的操作。例如,当使用“打开 Gmail”进行指示时,模型应正确识别主屏幕上的 Gmail 图标。此任务对于使用语言输入(如语音访问)控制移动应用非常有用。我们介绍了这个基准测试任务以前。
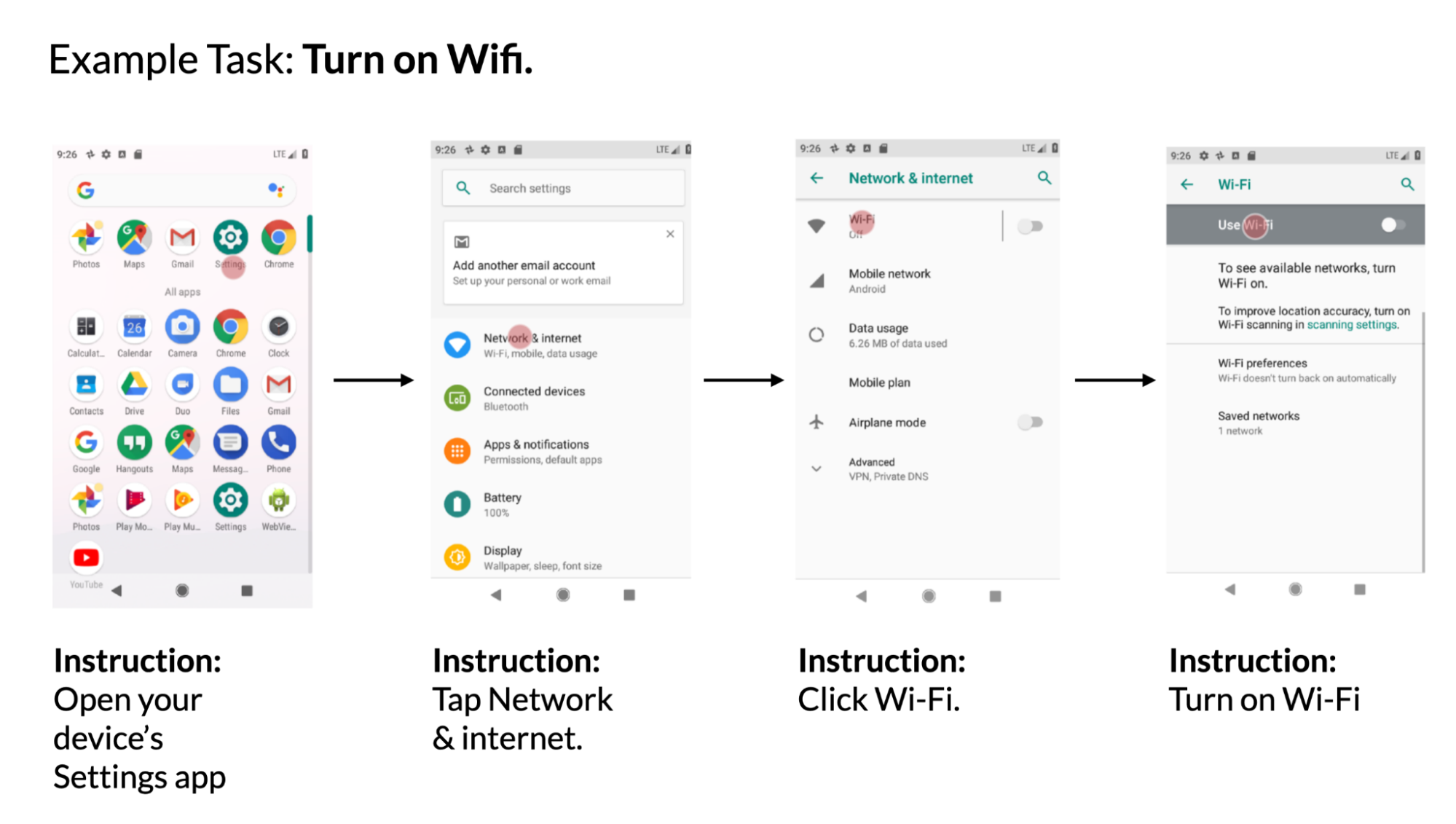 |
| 使用来自像素帮助数据集.数据集包含常见 UI 任务(如打开 wifi)的交互跟踪。每个跟踪都包含多个步骤和相应的说明。 |
我们使用来自Seq2Act纸。“部分”是指正确预测的各个步骤的百分比,而“完整”是指准确预测的整个交互跟踪的部分。尽管我们基于 LLM 的方法没有超过在海量数据集上训练的基准,但它仍然在仅通过两个提示数据示例就实现了卓越的性能。
| 模型 | 部分 | 完成 | ||||||
| 0发法学硕士 | 1.29 | 0.00 | ||||||
| 1 发法学硕士(跨应用程序) | 74.69 | 31.67 | ||||||
| 2 发法学硕士(跨应用程序) | 75.28 | 34.44 | ||||||
| 1 次 LLM(应用内) | 78.35 | 40.00 | ||||||
| 2发法学硕士(应用内) | 80.36 | 45.00 | ||||||
| Seq2Act | 89.21 | 70.59 |
我们的研究表明,在移动UI上对新颖的语言交互进行原型设计就像设计数据示例一样简单。因此,交互设计师可以快速创建功能模型,以与最终用户一起测试新想法。此外,开发人员和研究人员可以在投入大量精力开发新的数据集和模型之前探索目标任务的不同可能性。
我们研究了提示LLM在移动UI上启用各种对话交互的可行性。我们提出了一套提示技术,用于使LLM适应移动UI。我们对四个重要的建模任务进行了广泛的实验,以评估我们方法的有效性。结果表明,与由昂贵的数据收集和模型训练组成的传统机器学习管道相比,人们可以使用LLM快速实现基于语言的新型交互,同时实现竞争性能。
原文链接:使用LLM在移动设备上实现对话交互 (mvrlink.com)
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。
